1.1 Reproducible workflows
Reproducibility is the ability for any researcher to take the same data set and run the same set of software program instructions as another researcher and achieve the same results.
The goal is to create an exact record of what was done to a data set to produce a specific result. To achieve reproducibility, we believe that three things must be present:
- The un-processed data are connected directly to software code file(s) that perform data preparation techniques.
- The processed data are connected directly to other software code file(s) that perform the analyses.
- All data and code files are self-contained such that they could be given to another researcher to execute the code commands on a separate computer and achieve the same results as the original author.
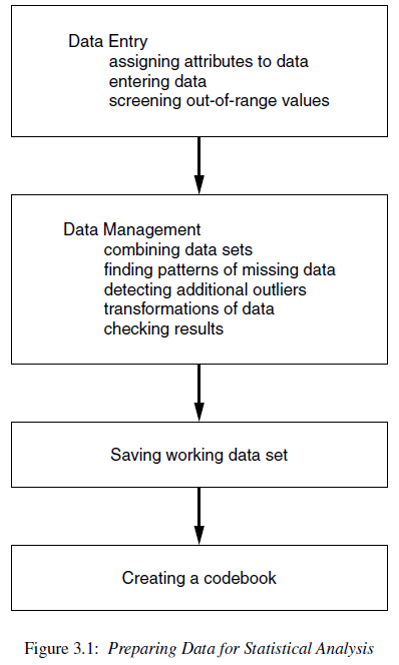
 Why do we need a codebook?
Why do we need a codebook?
- You are your own collaborator 6 months from now. Make sure you will be able to understand what you were doing.
- Investing the time to do things clearly and in a reproducible manner will make your future self happy.
- Comment your code with explanations and instructions.
- How did you get from point A to B?
- Why did you recode this variable in this manner?
- We need to record those steps (not just for posterity).
- This means your code must be saved in a script file.
- Include sufficient notes to yourself describing what you are doing and why.
- For R, this can be in a
.R,.Rmdor.qmdfile. I always prefer the latter. - For SPSS you can specify to
paste the syntaxand copy into a.spsscript file. - For SAS you’ll use a
.sasfile - For STATA this will be a
.dofile
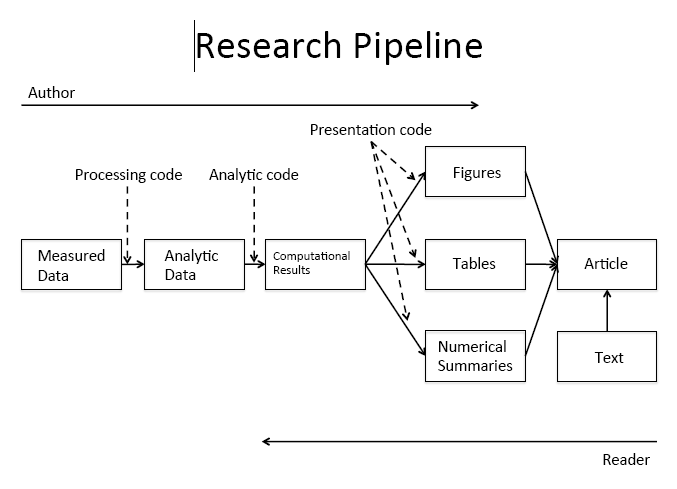
Figure Credits: Roger Peng
1.1.1 Literate programming
- Programming paradigm introduced by Knuth (1984)
- Explain the logic of the program or analysis process in a natural language,
- Small code snippets included at each step act as a full set of instructions that can be executed to reproduce the result/analysis being discussed.
Literate programming tools are integrated into most common statistical packages
- Markdown (R, Stata), Quarto (R, Python, others)
- \(\LaTeX\) (R, SAS, Stata)
Practicing reproducible research techniques using literate programming tools allows such major updates to be a simple matter of re-compiling all coded instructions using the updated data set.
The effort then is reduced to a careful review and update of any written results.
Using literate programming tools create formatted documents
- section headers
- bold and italicized words
- tables and graphics with built-in captions
in a streamlined manner that is fully synchronized with the code itself.
The author writes the text explanations, interpretations, and code in the statistical software program itself, and the program will execute all commands and combine the text, code and output all together into a final dynamic document.
What stages of the pipeline shown above can we conduct using literate programming tools?